


Impregnar a la IA de cultura y no sólo lengua
Los LLM no son un descubrimiento reciente. Su desarrollo abarca décadas de trabajo en campos como la inteligencia artificial y el procesamiento del lenguaje natural. Ya en la década de los 1950, cuando se desarrollaron los primeros ordenadores, comenzaron los intentos para comprender y generar lenguaje humano y se introdujo el concepto de “autómatas” y “gramáticas formales”, en gran parte gracias a pioneros como el lingüista Noam Chomsky y el informático Alan Turing. Estos primeros modelos utilizaban reglas gramaticales bastante estrictas y, por lo tanto, tenían una capacidad bastante limitada para manejar la ambigüedad y la variabilidad del lenguaje natural. Durante las décadas siguientes, se desarrollaron métodos estadísticos y basados en reglas probabilísticas, como los Modelos Ocultos de Markov y los algoritmos de árboles de decisión, que mejoraron la capacidad de las máquinas para analizar y generar lenguaje. Más adelante, en la década de 1990 y principios de los 2000, llegaron los modelos de lenguaje basados en redes neuronales recurrentes, que permitieron a las máquinas manejar secuencias de datos y contextos más largos, algo que mejoró sustancialmente su capacidad para procesar el lenguaje natural. Sin embargo, estas técnicas aún presentaban algunos problemas y desafíos, especialmente a la hora de afrontar la escalabilidad.
La verdadera revolución llegó en 2017 con la introducción de los “transformadores” (transformers), unas variables informáticas que utilizan un mecanismo para evaluar la importancia relativa de cada palabra en una frase, lo que facilita al mismo tiempo la comprensión de los datos de entrenamiento y la generación de texto más coherente, más convincente y, sobre todo, más contextualmente relevante. Los transformadores, descritos por primera vez por un equipo de ingenieros de Google, permiten un manejo del texto mucho más eficiente, dado que facilitan la detección de dependencias y relaciones entre palabras incluso a una gran distancia, algo que permite mejorar tanto la precisión como la versatilidad de los LLM. Los transformadores son tan importantes que, todavía a día de hoy, están detrás de las siglas del modelo de lenguaje más popular: el Generative Pre-trained Transformer, conocido comúnmente como GPT. Los primeros modelos de GPT se remontan a 2018, cuando la empresa OpenAI –que a mediados de 2024 había pasado a ser en gran parte propiedad de Microsoft, con un 49% de las acciones– lanzó el primer modelo de este tipo, seguido por las versiones mejoradas GPT-2, en 2019, y GPT-3, en 2020. Estos modelos demostraron una capacidad de generación de texto coherente y relevante sin precedentes, además de otras habilidades como la traducción y el resumen de textos, gracias al entrenamiento basado en enormes cantidades de texto.
El lanzamiento del “chatbot” ChatGPT al gran público, marcó un punto de inflexión en la popularización de los LLM. Entre otras cosas, porque no solo demostró la capacidad técnica de estos modelos, sino también su aplicabilidad práctica en diversas industrias mucho más allá de la informática, gracias a su habilidad para mantener conversaciones aparentemente naturales, responder preguntas complejas y realizar tareas específicas. Desde entonces, el desarrollo de nuevos modelos de lenguaje no ha dejado de crecer, con mejoras en la eficiencia, la precisión e incluso las interacciones y las respuestas en tiempo real que introduce la nueva versión de ChatGPT 4o. Sin embargo, el crecimiento de estos sistemas de inteligencia artificial también ha planteado nuevos retos –y nuevas preguntas–, como la preocupación sobre la transparencia y la ética de los LLM, la creación y la perpetuación de sesgos y el impacto climático y medioambiental que suponen tanto el entrenamiento como la utilización de esta tecnología. El propio Chomsky, pionero de los modelos de lenguaje hace más de 60 años, ha llegado a decir que ChatGPT en realidad promete algo imposible: no son herramientas de conversación, sino simplemente máquinas que analizan la probabilidad y los patrones de forma muy eficiente. Crean correlaciones, pero nunca explicaciones, no tienen capacidad crítica. Pero son realmente convincentes y, en cualquier caso, necesitarán una serie de regulaciones y políticas para garantizar un uso responsable, tal y como ha anticipado la Unión Europea con uno de los primeros marcos regulatorios para la inteligencia artificial para garantizar la seguridad y los derechos fundamentales de los ciudadanos.
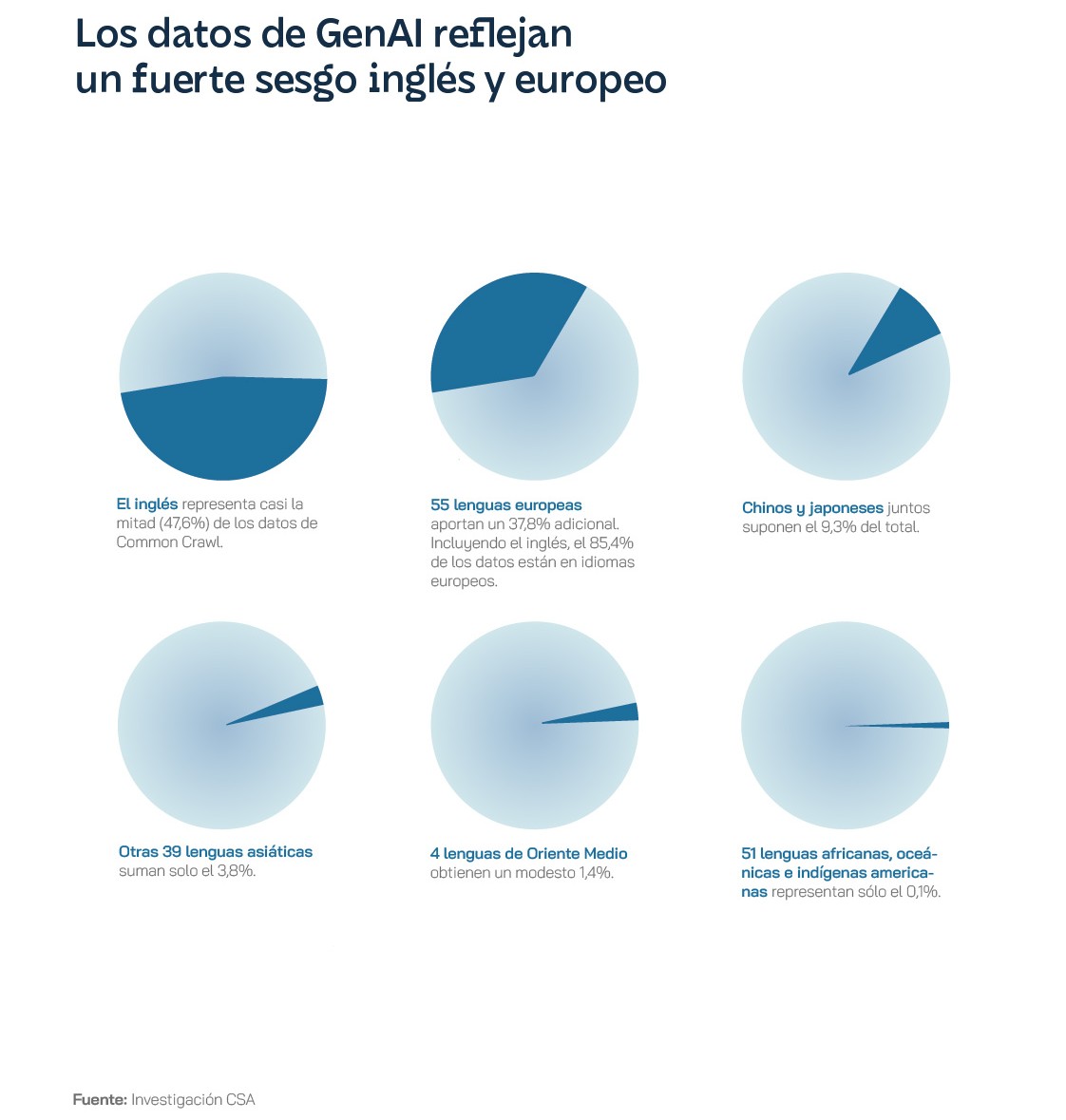
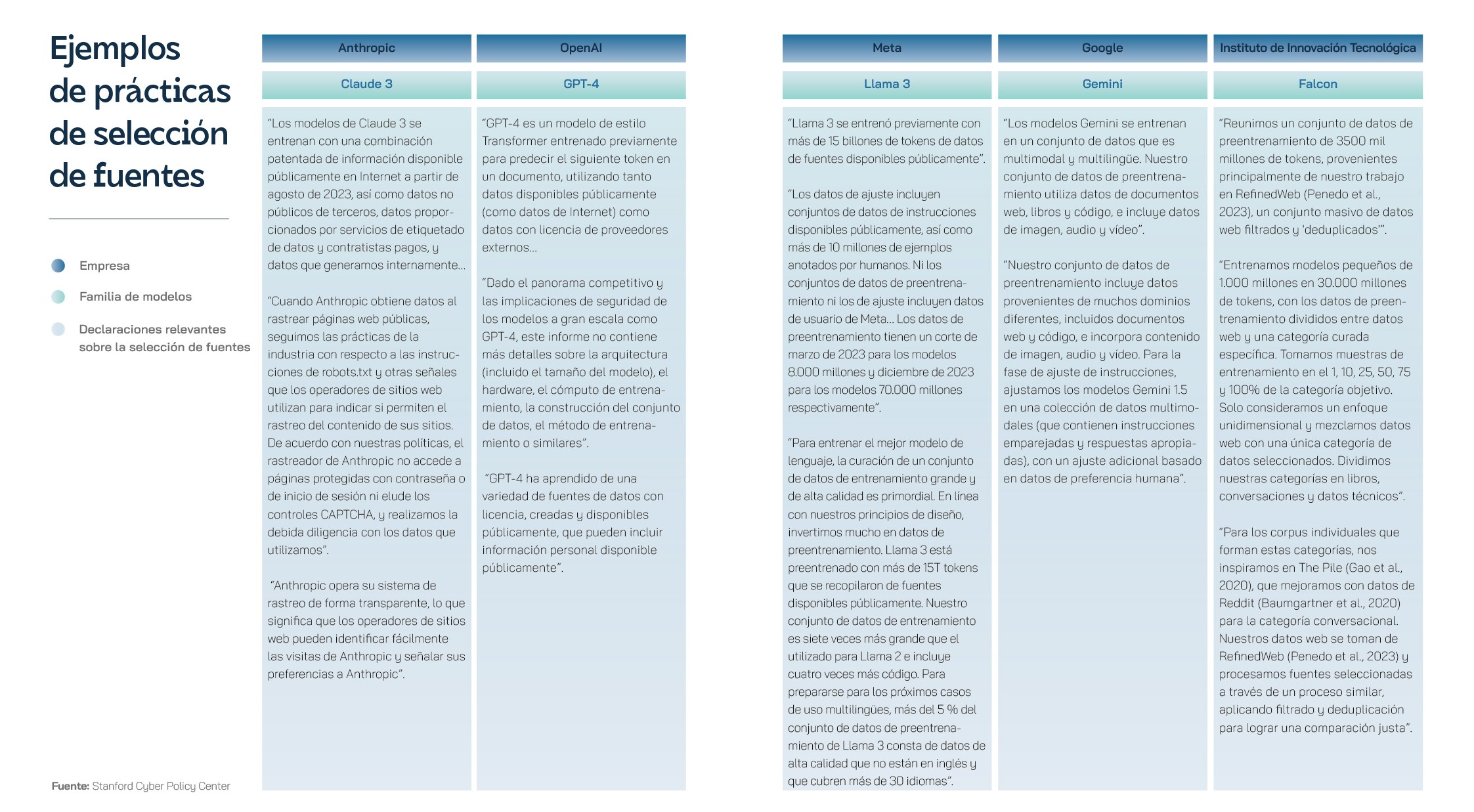
La evolución de los LLM se ha centrado en el entrenamiento y la educación con textos en inglés, lo que ha limitado significativamente su utilidad y, quizás todavía más importante, su aplicación a nivel global. Inicialmente, la mayoría de los avances en el procesamiento del lenguaje natural utilizaron el inglés por comodidad, así como por la disponibilidad de grandes catálogos de texto y recursos en este idioma. Sin embargo, muy pronto la comunidad investigadora empezó a reconocer las limitaciones de un modelo monolingüe y a valorar la importancia y la necesidad de desarrollar modelos robustos en otros idiomas, especialmente para fomentar la inclusión digital de una forma diversa e inclusiva. Los esfuerzos para entrenar a los LLM en otros idiomas se enfrentaron a grandes desafíos, sobre todo debido a la escasez de datos digitalizados. En este sentido, en los últimos años han surgido proyectos que aprovechan información traducida disponible de forma gratuita en internet para entrenar modelos de lenguaje multilingües, como el Europarl Corpus, basado en datos públicos publicados por el Parlamento Europeo, y Common Crawl, basado en el análisis de páginas web de todo el mundo. Este último también ha planteado problemas en cuestiones como el copyright y los derechos de autor, dado que utiliza fuentes de datos protegidos por diferentes tipos de licencias de propiedad intelectual y rara vez cita a los autores, tal y como reveló en exclusiva el Washington Post muy recientemente.
Los “transformadores” que permitieron el avance de modelos como ChatGPT también fueron una tecnología clave para entrenar al modelo mBERT, un modelo multilingüe que permitió comprender y generar texto en varios idiomas. Esto no solo mejoró la precisión de la inteligencia artificial en diferentes lenguas, incluido el español, sino que también facilitó la transferencia de conocimientos entre idiomas. Los entrenamientos en idiomas más allá del inglés permiten, en primer lugar, que las tecnologías avanzadas de inteligencia artificial sean accesibles a un público más amplio, independientemente de su lengua materna. Esto es esencial para garantizar la igualdad en temas de transformación digital y para asegurar un avance democrático de la tecnología, que permita que los beneficios de los LLM lleguen a todo el mundo. Además, entrenar modelos en múltiples idiomas mejora la capacidad intrínseca de estos sistemas para manejar el lenguaje y sus estructuras, además de aumentar su “bagaje” cultural y diversidad lingüística, un detalle vital no solo en tareas como la traducción automática y la búsqueda de información, sino especialmente en la interacción a través de conversaciones, donde un entrenamiento multilingüe puede garantizar una mayor naturalidad; porque los LLM entrenados en varios idiomas pueden captar matices y contextos específicos de cada lengua, incluidas particularidades culturales, refranes populares y expresiones.
Por último, un aspecto interesante –y, quizás, más inexplorado– de los modelos multilingües es el fomento de la investigación sobre lenguas subrepresentadas y en peligro de extinción. La inclusión de estos idiomas en los métodos de entrenamiento de la inteligencia artificial contribuye a una mejor documentación de estos idiomas y, en el futuro, podría promover su uso en el mundo digital, de modo que se contribuiría a su preservación y revitalización, de forma similar a los bancos de semillas y bancos de ADN que guardan información sobre especies en peligro de extinción para, potencialmente, rescatarlas en un futuro cercano.
El español es una de las lenguas más habladas en el mundo, la segunda en número de hablantes nativos y la cuarta en número de hablantes totales, según los datos de la base de datos mundial Ethnologue. En total, más de 560 millones de personas en los cinco continentes hablan español, un idioma que trasciende fronteras geográficas y culturales y, aún a día de hoy, desempeña un papel vital en la comunicación internacional y el desarrollo económico. Sin embargo, a pesar de estas estadísticas, el español estaba infrarrepresentado en los LLM, al menos hasta la llegada del impulso que permitieron los proyectos estratégicos para la recuperación y transformación económica (PERTE), en particular el programa para la “nueva economía de la lengua”, dotado con 1.100 millones de euros. Dentro de este programa de financiación se enmarca el sistema MarIA, un modelo de lenguaje creado por el Barcelona Supercomputing Center – Centro Nacional de Supercomputación a partir de los archivos digitales de la Biblioteca Nacional. El volumen y la capacidad de MarIA han logrado situar al español en los primeros puestos entre los LLM de acceso abierto, tan solo por detrás del inglés y el mandarín. Aunque la primera versión de MarIA utilizaba una tecnología, llamada RoBERTa, basada en modelos de lenguaje BERT –sistemas que generan una interpretación a partir de una secuencia de texto para, por ejemplo, clasificar documentos, responder a preguntas tipo test, encontrar similitudes semánticas en diferentes textos–, la última versión está creada con sistemas GPT-2 que permiten ampliar las capacidades del sistema, entre ellas la generación de nuevos textos a partir de una secuencia. Gracias a las propiedades de GPT, MarIA puede hacer resúmenes automáticos, redactar textos complejos a partir de “inputs” sencillos, generar preguntas y respuestas e, incluso, mantener diálogos complejos que dan la impresión de naturalidad.
Esta inteligencia artificial ha sido entrenada con más de 135.000 millones de palabras, procedentes de distintos archivos guardados y catalogados por la Biblioteca Nacional, que suponen un total de unos 570 gigabytes de datos. Además, han sido necesarias más de 9,7 trillones de operaciones del ordenador Mare Nostrum 4, en el Barcelona Supercomputing Center, para filtrar y catalogar todos los escritos analizados, eliminar todos los fragmentos poco relevantes (como figuras, frases inacabadas, anglicismos y segmentos en otros idiomas) y, por supuesto, entrenar las redes neuronales del modelo. Según las fuentes del Ministerio para la Transformación Digital, modelos de LLM como MarIA “multiplicarán las oportunidades económicas para las empresas y la industria tecnológica española.” Estos sistemas pueden ser de gran utilidad también para las administraciones públicas, gracias a aplicaciones como la escritura, el resumen de documentos legales, y la búsqueda de información en grandes bases de datos de texto. Hasta ahora, todos estos sistemas estaban desarrollados mayoritariamente en inglés, lo que limitaba las aplicaciones en español por las diferencias léxicas y, sobre todo, gramaticales entre los dos idiomas.
Para Elena González Blanco, filóloga y experta en inteligencia artificial, el desarrollo de LLM en español es “una misión social [para] darle a nuestra lengua el estatus que se merece en tecnología”. Por eso fundó la empresa Clibrain, que trabaja para aumentar el entrenamiento de los modelos de lenguaje con catálogos más amplios en español, incluyendo la Biblioteca Nacional, como el sistema MarIA del Barcelona Supercomputing Centre, pero también la Real Academia Española, academias de la lengua de Latinoamérica y datos locales, disponibles de forma pública en España y otros países, como periódicos, blogs, páginas web y libros digitales. En 2023, la empresa Clibrain presentó su propio LLM basado en GPT-3, al que bautizaron con un nombre muy ibérico: LINCE. Este modelo es el resultado de un riguroso proceso de desarrollo y entrenamiento de modelos de lenguaje que utiliza un banco de datos completamente nuevo para ofrecer unos resultados sobresalientes en español. Clibrain ofrece dos versiones de su modelo LINCE, ZERO, una versión abierta publicada bajo una licencia open source basada en más de 7.000 millones de parámetros, que permite su utilización en aplicaciones sin fines comerciales y LINCE, una versión “para empresas” con un tamaño seis veces mayor y una capacidad aún más robusta para el procesamiento del español, incluida la interpretación de dialectos y rasgos característicos de zonas específicas. Además, Clibrain también ha publicado una API –un conjunto de reglas y protocolos que permite que distintos programas informáticos se comuniquen, fundamental en el desarrollo de software con capacidades integradas– que permite la incorporación de LINCE en aplicaciones externas, de una forma similar a la adoptada por OpenAI y ChatGPT. De este modo, han desarrollado aplicaciones como Clichat, Clibot y Clicall, que permiten interactuar con LINCE en forma de chats y aplicaciones de productividad.
Mucho más recientemente, a mediados de abril de 2024, el Gobierno también anunció una nueva colaboración con la multinacional informática IBM para fomentar el desarrollo de modelos no solo en español, sino también en las otras lenguas cooficiales del estado – catalán, valenciano, gallego y euskera. Ampliar los modelos disponibles en español ayudará, según IBM, a potenciar una utilización más ética de la inteligencia artificial, así como a la democratización y el crecimiento sostenible de esta tecnología tanto en España como en Latinoamérica y otros países de habla hispana. En este sentido, la Estrategia Nacional de Inteligencia Artificial, presentada en mayo de 2024, también supone un avance significativo en términos de regulación de los riesgos y las implicaciones éticas y garantiza un desarrollo que prioriza los usos en la investigación y la industria, gracias a una dotación presupuestaria de 1.500 millones de euros en los próximos dos años. Por lo tanto, parece que el futuro de la inteligencia artificial y, en particular, los modelos de lenguaje en español es prometedor, con un gran potencial para transformar la forma en que interactuamos tanto con la tecnología como entre nosotros en el mundo hispanohablante. Se espera que el avance de los LLM entrenados en español, junto con mejoras en la capacidad de procesamiento y la digitalización –que afecta directamente a la disponibilidad de datos– conduzca a sistemas más sofisticados y adaptables, listos para comprender y generar texto en español con mayor precisión y naturalidad.
Tecnología con variantes lingüísticas
El uso del español crece a una media del 7,5% anual. El Perte de Nueva Economía de la Lengua se diseñó con el objetivo de conseguir una inteligencia artificial (IA) capaz de procesar adecuadamente en español, que “piense en español”, afirma textualmente, para, a partir de ahí, crear una industria basada en tecnologías como el procesamiento del lenguaje natural, la traducción automática y los sistemas conversacionales. El reto presenta muchos factores de complejidad. Diferenciar las múltiples variedades de español exige conocer no sólo las variantes léxicas, sino también la fonética e incluso el contexto en el que se utilizan determinadas expresiones, matices que se pierden fácilmente en la traducción. Se da la paradoja de que existe gran cantidad de datos disponibles en español, pero muchos no se pueden utilizar porque a menudo son propiedad de empresas privadas y, si pertenecen a instituciones públicas y culturales, se encuentran aislados en silos y no son de fácil acceso.
Hay dificultades a superar que son estrictamente materiales, de disponibilidad de recursos. El desarrollo de modelos de lenguaje de vanguardia requiere de la participación de expertos en inteligencia artificial, lingüística computacional, aprendizaje automático y otros campos relacionados, y nuestro país sufre una escasez de programadores e ingenieros de datos, además de lingüistas y psicólogos. El porcentaje de graduados en ramas STEM afines a la IA, apenas alcanza el 11% del total de matriculados en universidades y centros públicos. De hecho, ha disminuido un 14% entre 2012 y 2022, un fenómeno con apenas un par de casos similares en el conjunto de países europeos. El resultado es que, pese a los voluntariosos mensajes institucionales, no somos una potencia en IA. A finales de 2023, España sólo había desarrollado un modelo fundacional, frente a los 109 de Estados Unidos; ese año movilizó una inversión privada de 360 millones de dólares en IA (Estados Unidos, 67.220 millones; Reino Unido, 3.780; y Alemania 1.910); y había creado 21 nuevas compañías de IA (Estados Unidos, 897; China, 122; Reino Unido, 104; y Alemania, 76). Además, las empresas de tecnología en lengua española son generalmente más pequeñas que las del mundo anglosajón y se orientan a funciones específicas como la traducción.
Se prevé que el mercado mundial de IA conversacional alcance los 41.400 millones de dólares en 2030, con un crecimiento anual compuesto del 23,6% entre 2022 y 2030. Los chatbots y los asistentes virtuales interactivos podrían ser los grandes beneficiados de esa expansión, gracias al salto exponencial que implica la IA generativa, desde los primeros días de los sistemas basados en reglas con respuestas predefinidas. La demanda podría ejercer, por consiguiente, un poderoso papel de locomotora de la innovación y el desarrollo del sector. Para empezar, no existe una IA capaz de procesar las numerosas variantes dialectales del idioma español, teniendo en cuenta circunstancias geográficas, sociales o contextuales. Desarrollarla, incluyendo las lenguas cooficiales, implicaría la creación de modelos de lenguaje de alto valor tanto de dominio general como especializados en ámbitos de alto impacto, como la sanidad, la educación o el Derecho.
Como se ha dicho, una de las opciones pasa por evolucionar el modelo del lenguaje “MarIA”, el primer sistema de inteligencia artificial experto en comprender y escribir en lengua española, creado en el marco del Plan de Impulso de Tecnologías del Lenguaje Natural en colaboración con el Centro Nacional de Supercomputación y la Biblioteca Nacional de España. En paralelo, un desarrollo de la IA en español requeriría también de introducir un test de referencia de evaluación de comprensión del lenguaje general, similar al Superglue del inglés, y una certificación del buen uso del español en las herramientas tecnológicas y de IA. En el caso de las lenguas cooficiales, hay proyectos en marcha, como Aina, Nós y el Plan de Tecnologías del Lenguaje en euskera, entre otros, que se suman a otras iniciativas en este ámbito en los países iberoamericanos, especialmente en el contexto administrativo.
El proyecto Alia, que se desarrolla en el MareNostrum V del Barcelona Supercomputing Center (BSC) trabajará directamente en español y en las lenguas cooficiales del Estado, sin traducción. Será una infraestructura abierta, pública y transparente, entrenada con una base de datos diseñada para recibir aportaciones de instituciones como universidades o colegios profesionales, que puedan ofrecer el contenido de sus propios repositorios de información. Para trabajar con las lenguas con menos recursos, como el euskera y el gallego, IBM Research planea utilizar “datos sintéticos”, textos generados por otras IA destinados a enriquecer la base de datos de entrenamiento. Junto a ello, la Real Academia Española se alió en 2021 para el proyecto Lengua Española e Inteligencia Artificial (LEIA) con compañías como Telefónica, Google, Amazon, Microsoft, X y Facebook. La iniciativa incluye la creación de asistentes de voz, procesadores de texto, buscadores, chatbots, sistemas de mensajería instantánea y redes sociales, siguiendo los criterios sobre buen uso del español. LEIA nació con el objetivo de ayudar a la recopilación de material basado en la diversidad de las variedades geográficas del español, la accesibilidad de las herramientas de IA y la digitalización de los fondos propios de la RAE. En su nueva etapa, iniciada en primavera de 2024, ha incorporado la creación de un observatorio de neologismos, tecnicismos, términos y variaciones del español, y de herramientas de verificación ortográfica, gramatical y léxica y de respuesta a consultas lingüísticas.
Todos estos pasos son relevantes porque la investigación científica ha demostrado que la lengua raíz de un modelo de IA sí incide en su comportamiento. Aleph Alpha, una startup de Heidelberg (Alemania), creó uno de los modelos de lenguaje de IA más potentes del mundo, capaz de hablar con fluidez inglés, alemán, francés, español e italiano, pero se descubrió que sus respuestas podían diferir de las producidas por programas similares desarrollados en Estados Unidos. En inglés, la palabra “the” se usa para identificar un sustantivo específico, mientras que, en otros idiomas, como el español, el artículo definido se usa con menos frecuencia y eso complica la creación de indicaciones que funcionen en ambos idiomas. Cada lengua parte estándares culturales diversos, hacer preguntas directas puede ser un gesto de mala y buena educación según el idioma que se use. Los modelos lingüísticos entrenados en el contenido chino de internet reflejan la censura que está en el origen de esa información.
La aprobación de la Ley de Inteligencia Artificial de la UE contribuirá a establecer el marco de trabajo en el futuro. La disparidad, especialmente en términos de recursos disponibles, pone en duda el estatus «agnóstico de la lengua» en los modelos actuales. A finales de la pasada década, existían más de 190 corpus desarrollados para español, lenguas cooficiales y distintas variantes. El Corpus del Español del Siglo XXI (CORPES XXI), impulsado por la Real Academia Española (RAE), sería el corpus de referencia, con recursos de calidad anotados y detallados. El problema es su tamaño, en relación con la información digitalizada en inglés, pero al menos muestra un nivel de solvencia superior a la media del resto del mundo. En una auditoría manual de la calidad de 205 corpus específicos de idiomas publicados con cinco conjuntos de datos públicos principales (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4) se constató que al menos 15 de ellos no tenían texto utilizable y 87 contaban con menos de un 50% de oraciones de calidad aceptable. Muchos estaban mal etiquetados o utilizaban códigos lingüísticos no estándar o ambiguos. En el caso de ParaCrawl-2, puede considerarse uno de los más avanzados, especialmente después de la inclusión de nuevos pares de lenguas: los formados por el español y las tres lenguas regionales reconocidas en el país (catalán, vasco y gallego) o las dos lenguas noruegas (bokml y nynorsk).
Se estima que hay en torno a 1.000 veces más datos en inglés que en español y la desproporción se acentúa en el caso de las lenguas cooficiales. El 5,6 % del contenido en internet está en castellano, comparado con solo el 0,1% en catalán/valenciano. El poder de la tecnología, sin embargo, puede compensar la diferencia de partida. Esa es la gran oportunidad para los innovadores y quienes sepan identificar la necesidad a cubrir. Pese haber sido entrenado en inglés, un experimento demostró que, al pedírsele un titular para un artículo sobre Valencia, GPT-3 era capaz de escribir en valenciano considerando las particularidades culturales implícitas en esa habla. En 2023, ChatGPT tenía una precisión promedio del 63,41% en 10 categorías de razonamiento diferentes: razonamiento lógico, razonamiento no textual y razonamiento de sentido común, lo que lo convertía en un razonador poco confiable. Un año después, Open AI tradujo el punto de referencia MMLU (un conjunto de 14.000 problemas de opción múltiple que abarcan 57 temas) a 26 idiomas mediante Azure Translate: en 24 de los idiomas evaluados, superó el rendimiento en inglés de GPT-3.5 y de otros LLM (Chinchilla, PaLM), incluso en idiomas de bajos recursos como letón, galés y suajili. El inglés es el idioma con mayores recursos en muchos órdenes de magnitud, pero el español, el chino, el alemán y varios idiomas más cuentan con un volumen de documentos lo suficientemente alto como para construir modelos lingüísticos igual de sofisticados.
A nivel global, el problema no es estrictamente tecnológico, sino de visibilidad. Las comunidades con acceso limitado a Internet están subrepresentadas online, lo que distorsiona los datos textuales disponibles para entrenar herramientas de IA generativa y alimenta un fenómeno conocido como la transferencia de prestigio[26] , que establece que el inglés estadounidense es el “estándar” y el modo dominante de discurso, y cualquier desviación estilística en la pronunciación o la gramática se percibe como inferior o incorrecta. La última versión, ChatGPT-4, obtuvo una puntuación del 85% en una prueba común de preguntas y respuestas en inglés, pero en telugu, un idioma indio hablado por casi 100 millones de personas, se mantuvo en el 62%.
En general, el rendimiento de ChatGPT es habitualmente mejor para indicaciones en inglés, especialmente para tareas de nivel superior que requieren habilidades de razonamiento más complejas, aunque los textos de entrada estén redactados o esperen recibir la respuesta en a otros idiomas. Su comportamiento empeora al responder preguntas objetivas o resumir textos complejos en idiomas distintos del inglés, en esas circunstancias es más probable que invente información. Los modelos funcionan mejor en tareas que implican pasar de un idioma X al inglés, que en tareas que implican pasar del inglés a ese idioma. En un ejercicio de abril de 2023, NewsGuard proporcionó a ChatGPT-3.5 siete mensajes en inglés, chino simplificado y chino tradicional, y le pidió que produjera noticias que promovieran narrativas de desinformación relacionadas con China. Para el ejercicio en inglés, ChatGPT se negó a presentar afirmaciones falsas en seis de siete mensajes. Sin embargo, produjo los artículos falsos en chino simplificado y en chino tradicional las siete veces. Precisamente en el ámbito de la información periodística, y para solventar las dudas sobre el uso de recursos protegidos por propiedad intelectual, OpenAI ha incorporado alianzas que incluyen a la española Prisa Media, la francesa Le Monde y la alemana Axel Springer, que se suman a sus colaboraciones con American Journalism Project, para apoyar iniciativas innovadoras de noticias locales, y The Associated Press.
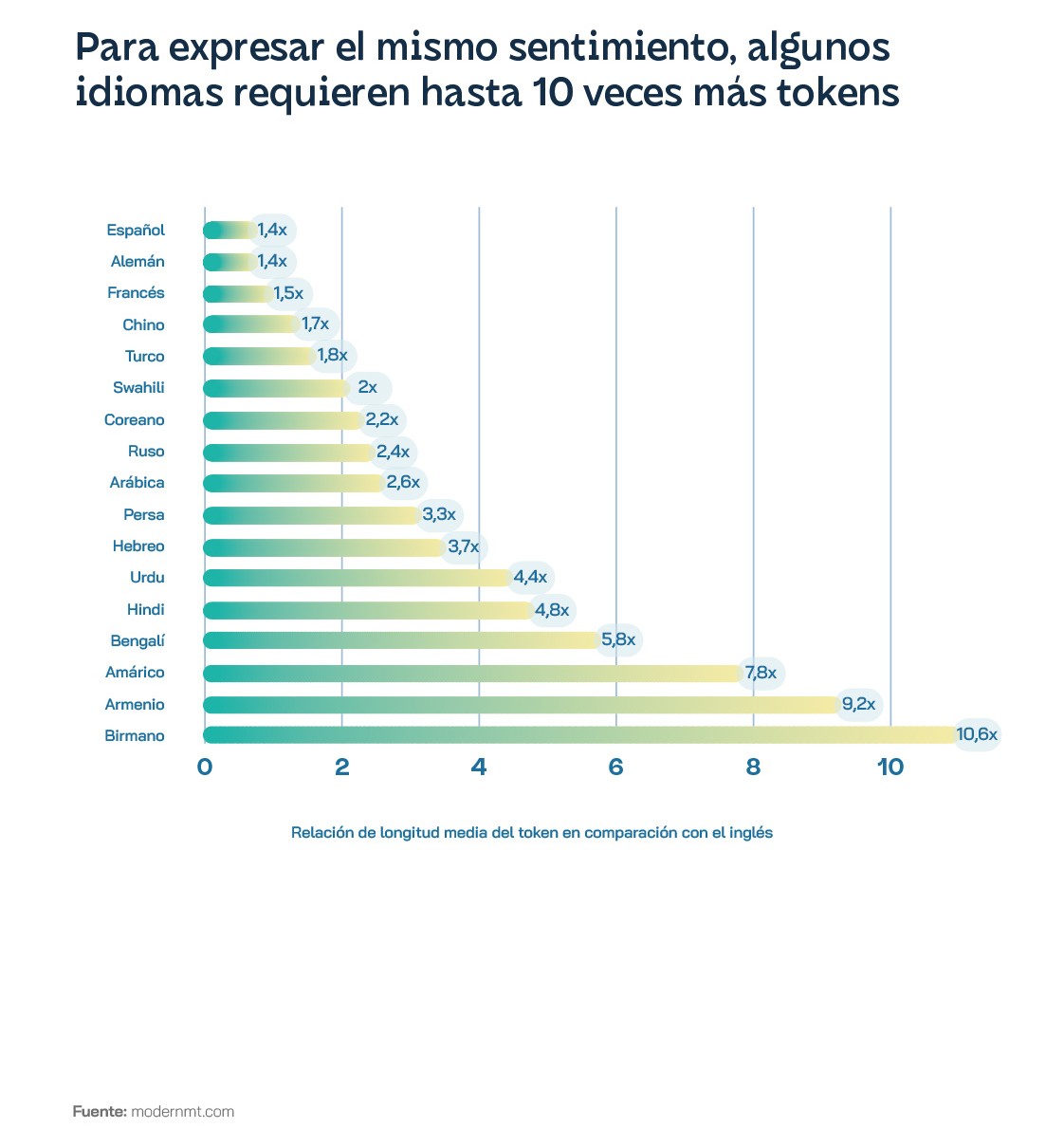
Además del problema de la escasez de datos hay que afrontar el incremento de costes: usar GPT-4 en idiomas distintos del inglés puede costar hasta 15 veces más, a causa de la tokenización, pese a resultar menos efectivo. Idiomas como el hindi y el bengalí, hablados por más de 800 millones de personas, presentan una longitud simbólica media que supera en aproximadamente cinco veces la del inglés, el idioma armenio lo rebasa en nueve veces y el birmano en más de 10 veces. Todo eso se traduce en tokens, cuyo modelo de asignación favorece desproporcionadamente los idiomas con escritura latina y fragmenta excesivamente a las escrituras menos representadas. Lo cual no es una cuestión menor teniendo en cuenta que Estados Unidos solo representó el 10% del tráfico enviado a ChatGPT entre enero y marzo de 2023. Los modelos de lenguaje han pasado de ser prototipos de investigación a productos comercializados ofrecidos como API web, que cobran a sus usuarios según el uso, o por ser más precisos, por la cantidad de «tokens» procesados por los modelos de lenguaje subyacentes.
Hay investigadores que sostienen que, en las actuales circunstancias, resulta más razonable construir modelos dirigidos a satisfacer tareas específicas más pequeños para problemas de PLN (procesamiento de lenguaje natural) que se pueden alojar localmente y funcionar a costes más bajos. RigoBERTa es un modelo de lenguaje en español del Instituto de Ingeniería del Conocimiento (IIC) de la Universidad Autónoma de Madrid diseñado para adaptarse a diferentes dominios del lenguaje, como legal o salud, para mejorar las aplicaciones del PLN. Está pensado para aplicarse a un nivel productivo o empresarial y no a nivel usuario como la mayoría de los modelos generativos. Curiosamente, el rendimiento de Chat GPT para idiomas de bajos y extremadamente bajos recursos en algunas tareas es, en ocasiones, mejor o comparable al de los idiomas de recursos altos o medios. Lo cual podría indicar que el tamaño de los datos podría no ser el único factor que determina su rendimiento: también influye la tarea objetivo y las similitudes y las relaciones de un idioma con respecto a otros dominantes en los datos de capacitación para LLM.
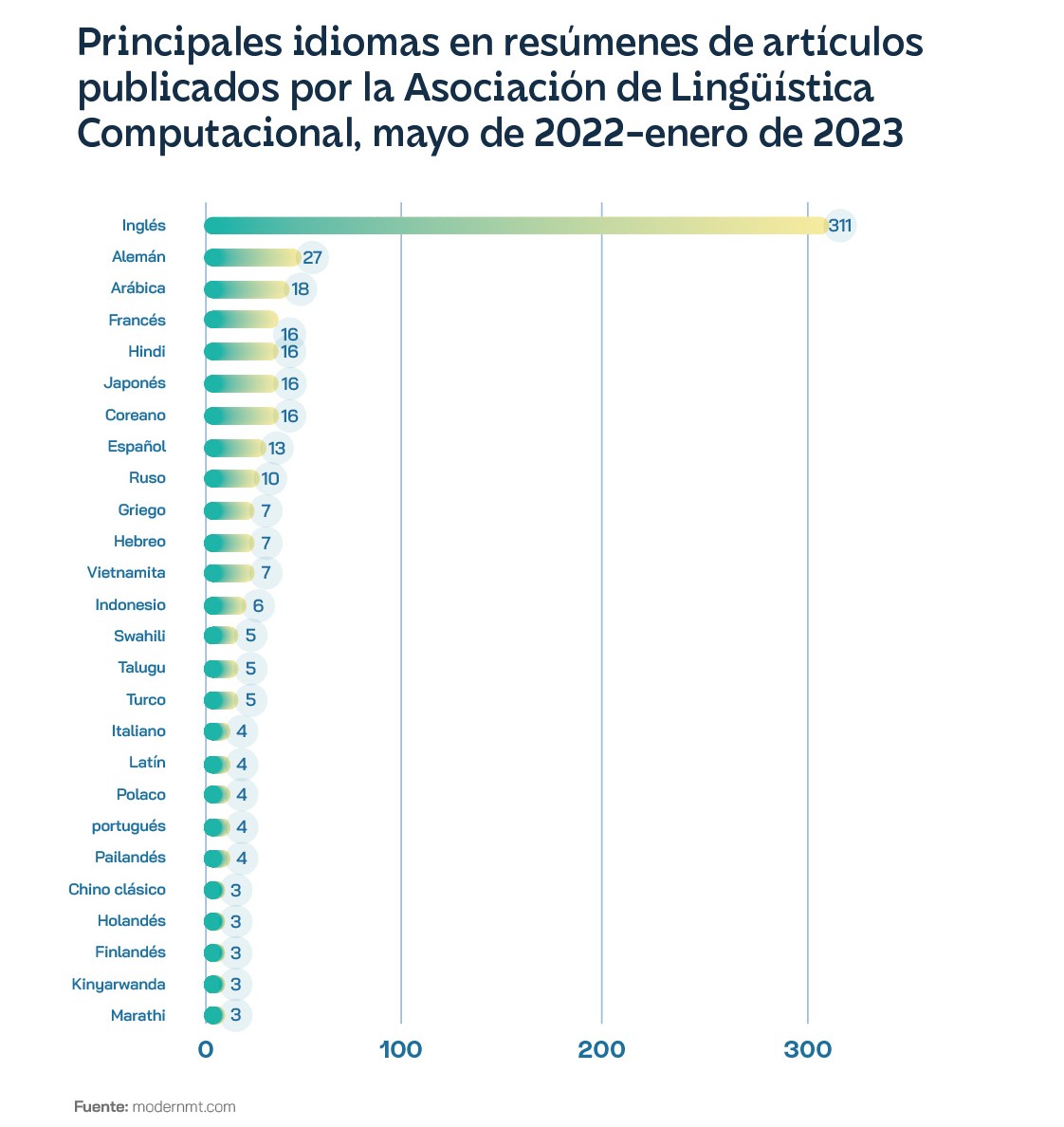
El inglés es el idioma principal de Internet con el 63,7% de los sitios web, a pesar de que solo lo habla el 16% de la población mundial. Entre los artículos científicos sobre PLN, el inglés se menciona diez veces más que el siguiente, el alemán. A medida que crece la investigación se incrementan los datos etiquetados, que pueden usarse para la calidad de los modelos, en lo que acaba siendo un círculo virtuoso para la PLN en inglés, pese a que hay otros seis idiomas que podrían considerarse de altos recursos: las lenguas idiomas oficiales de la ONU, menos el ruso y más el japonés. Hasta las empresas de tecnología son conscientes de esa situación y vienen trabajando en ampliar la cantidad de modelos de lenguaje en los que funcionan sus soluciones. Lo hacen creando más conjuntos de datos, con proyectos como No Language Left Behind de Facebook y la Iniciativa 1000 Idiomas de Google. La arquitectura del modelo BERT, de esta última compañía, uno de los más populares y más baratos de entrenar, se ha utilizado para francés (CamemBERT), italiano (AlBERTo), árabe (AraBERT), holandés. (BERTje), vasco (BERTeus), maltés (BERTu) y suajili (SwahBERT), entre otros. Preocupada por las implicaciones que podría tener en la eficacia de los sistemas de defensa, la Agencia de Proyectos de Investigación Avanzados de Defensa (DARPA) de Estados Unidos financió el programa Idiomas de bajos recursos para incidentes emergentes (LORELEI) en 2014. En lugar de utilizar modelos monolingües para realizar tareas de PNL, los investigadores suelen utilizar modelos de idiomas multilingües, como el mencionado mBERT de Google y XLM-R de Meta, que se entrenan a partir textos de muchos idiomas diferentes a la vez en la misma tarea de rellenar espacios en blanco. Se entiende que pueden inferir conexiones entre idiomas y actuar así como una especie de puente entre los de altos y bajos recursos. Sin embargo, la realidad es que los modelos multilingües funcionan mediante la transferencia entre contextos lingüísticos, y a menudo eso supone que los idiomas con mayores recursos sobrescriben a los de menores recursos. El español utiliza más adjetivos y analogías que el inglés para describir situaciones extremas, por lo que un algoritmo de detección de sentimientos en inglés podría caracterizar erróneamente un texto escrito en español. Los idiomas no necesariamente se informan entre sí, son áreas superpuestas, pero distintas del conjunto de datos, y el modelo no tiene manera de comparar si ciertas frases o predicciones difieren entre esas áreas. En definitiva, cuantos más idiomas se entrena un modelo multilingüe, menos puede capturar los rasgos únicos de cualquier idioma específico. Es lo que se conoce como la maldición del multilingüismo.
Tecnología de la lengua sobre el terreno
El desafío de la inteligencia artificial en español se ha abordado a lo largo de los últimos años como un reto de impulso público, al que se han sumado corporaciones tecnológicas como Telefónica e IBM como proveedoras de infraestructura de soporte y servicio de I+D, además de entidades como el Barcelona Supercomputing Center. Para el director del Instituto Cervantes, desde el ámbito de las principales instituciones culturales españolas el reto lingüístico y cultural más importante del siglo XXI es “enseñar español a las máquinas y que estas nos ayuden a enseñarlo”. Desde su institución, continúa en unas reflexiones publicadas en la web del instituto, “promoveremos el diseño de sistemas de IA robustos, fiables y transparentes que prevengan un uso inapropiado o torticero de la tecnología, en especial a través de la expresión confusa, ambigua o sesgada en el lenguaje”. Según Luis García Montero, “los algoritmos han de ampliar el atractivo de nuestra lengua en toda su diversidad, de la cultura panhispánica que la acompaña y de nuestras industrias comunes”. En última instancia, “las máquinas usarán fórmulas, palabras, imágenes, diseños y expresiones claras utilizando todos los matices de nuestros idiomas, la importancia del contexto y la forma en la que los seres humanos nos comunicamos entre nosotros”. La principal medida puesta en marcha para ejercer esa gobernanza ha sido la creación del Observatorio Global del Español, que celebró la primera reunión de su comisión ejecutiva en marzo de 2024. Desde el Instituto Cervantes se espera que sirva, entre otras cosas, para determinar la forma en la que se debe apoyar la inteligencia artificial y el lenguaje de las máquinas para que no creen sesgos supremacistas, entre otros problemas y riesgos que entrañan.
En paralelo, el proyecto LEIA (Lengua Española e Inteligencia Artificial) entraba también en 2024 en su segunda fase, bajo el liderazgo de la Real Academia Española y con la participación como socios tecnológicos de Fujitsu, que se basa en las soluciones de Amazon Web Services (AWS), y de la norteamericana VASS. No hay tecnología española, por el momento. En esta etapa se creará un observatorio de neologismos, términos y variaciones del español, una herramienta capaz de detectar automáticamente, en el universo digital y a partir de un buen número de fuentes, palabras y expresiones que no están registradas todavía en el Diccionario de la lengua española (DLE), ya sean neologismos, derivados, tecnicismos, regionalismos y extranjerismos. Por otra parte, se creará un verificador lingüístico en abierto alojado en la página de LEIA y accesible desde la web de la RAE. Permitirá a los usuarios introducir un texto para comprobar si es correcto desde un punto de vista ortográfico, gramatical y léxico. En relación con esta iniciativa, el proyecto prevé también la creación de una herramienta para dar respuesta a las dudas lingüísticas de los hispanohablantes. La segunda fase de LEIA incluye, asimismo, la recopilación de material representativo de las distintas variedades geográficas del español, especialmente léxico y oral. Para ello, una sección interactiva permitirá aportar información en relación con imágenes, textos u otros elementos que se les muestren. La participación ciudadana, en ese sentido, será clave porque se pedirá a los usuarios que describan una imagen con su propia voz y con ello se creará un corpus oral para entrenar a los sistemas o aplicaciones en los distintos acentos. LEIA pondrá disposición pública, de manera abierta, los materiales utilizados para generar el proyecto, desde códigos fuente a datos o corpus de entrenamiento, con la intención de impulsar la industria de las tecnologías del lenguaje en español.