


Impregnating AI with culture and not just language
LLMs are not a recent discovery. Their development spans decades of work in fields such as artificial intelligence and natural language processing. As early as the 1950s, when the first computers were developed, attempts to understand and generate human language began and the concept of "automata" and "formal grammars" was introduced, largely thanks to pioneers such as the linguist Noam Chomsky and the computer scientist Alan Turing. These early models used rather strict grammatical rules and were therefore rather limited in their ability to handle the ambiguity and variability of natural language. Over the following decades, statistical and probabilistic rule-based methods such as Hidden Markov Models and decision tree algorithms were developed, which improved the ability of machines to parse and generate language. Later, in the 1990s and early 2000s, came language models based on recurrent neural networks, which allowed machines to handle longer sequences of data and contexts, something that substantially improved their ability to process natural language. However, these techniques still presented some problems and challenges, especially when it came to scalability.
The real revolution came in 2017 with the introduction of the "transformers" (transformers), computer variables that use a mechanism to evaluate the relative importance of each word in a sentence, making it easier both to understand the training data and to generate more coherent, more compelling and, above all, more contextually relevant text. Transformers, first described by a team of Google engineers, enable much more efficient text handling by making it easier to detect dependencies and relationships between words even at great distances, improving both the accuracy and versatility of LLMs. Transformers are so important that, to this day, they are still behind the acronym of the most popular language model: the Generative Pre-trained Transformer, commonly known as GPT. The first GPT models date back to 2018, when the company OpenAI - which by mid-2024 had become largely owned by Microsoft, with 49% of the shares - released the first such model, followed by enhanced versions GPT-2 in 2019 and GPT-3 in 2020. These models demonstrated an unprecedented ability to generate coherent and relevant text, as well as other skills such as text translation and summarisation, thanks to training based on huge amounts of text.
The launch of the ChatGPT chatbot to the general public marked a turning point in the popularisation of LLMs. Among other things, because it not only demonstrated the technical capability of these models, but also their practical applicability in various industries far beyond IT, thanks to their ability to carry on seemingly natural conversations, answer complex questions and perform specific tasks. Since then, the development of new language models has continued to grow, with improvements in efficiency, accuracy and even real-time interactions and responses introduced by the new version of ChatGPT 4o. However, the growth of these artificial intelligence systems has also raised new challenges - and new questions - such as concerns about the transparency and ethics of LLMs, the creation and perpetuation of bias, and the climate and environmental impact of both the training and use of this technology. Chomsky himself, a pioneer of language modelling more than 60 years ago, has gone so far as to say that ChatGPT actually promises the impossible: they are not conversational tools, but simply machines that analyse probability and patterns very efficiently. They create correlations, but never explanations, they have no critical capacity. But they are really convincing and, in any case, they will need a set of regulations and policies to ensure responsible use, as the European Union has anticipated with one of the first regulatory frameworks for artificial intelligence to ensure the safety and fundamental rights of citizens.
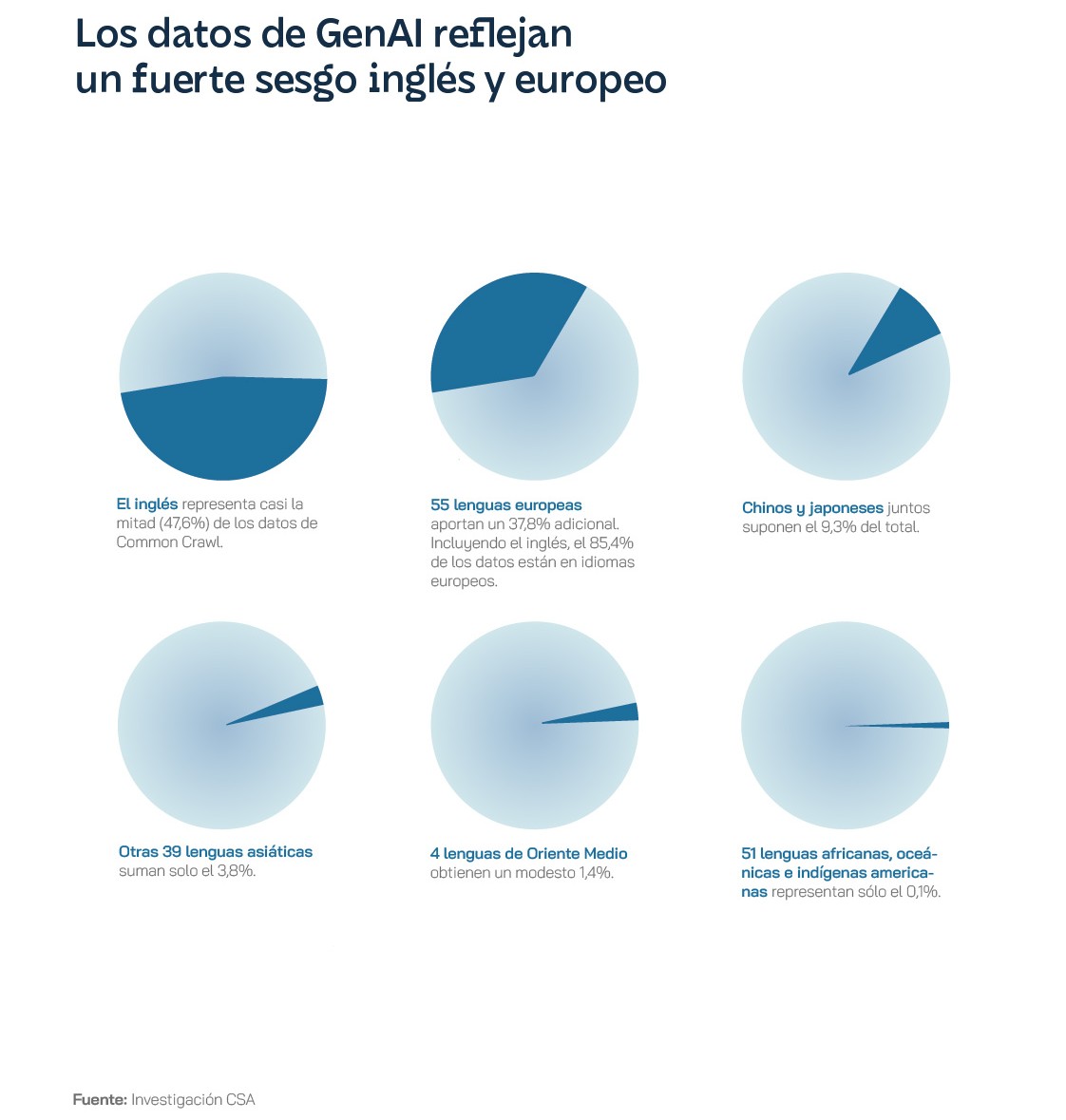
The evolution of LLMs has focused on training and education with English texts, which has significantly limited their usefulness and, perhaps more importantly, their application globally. Initially, most developments in natural language processing used English for convenience, as well as the availability of large text catalogues and resources in English. However, very soon the research community began to recognise the limitations of a monolingual model and to appreciate the importance and need to develop robust models in other languages, especially to foster digital inclusion in a diverse and inclusive way. Efforts to train LLM in other languages faced major challenges, especially due to the scarcity of digitised data. In this regard, recent years have seen the emergence of projects that take advantage of translated information freely available on the internet to train multilingual language models, such as the Europarl Corpus, based on public data published by the European Parliament, and Common Crawl, based on the analysis of websites from around the world. The latter has also raised copyright issues, as it uses data sources protected by different types of intellectual property licences and rarely cites authors, as the Washington Post exclusively revealed very recently.
The "transformers" that enabled the advancement of models such as ChatGPT were also a key technology for training the mBERT model, a multilingual model that enabled understanding and generating text in multiple languages. This not only improved the accuracy of artificial intelligence in different languages, including Spanish, but also facilitated knowledge transfer between languages. Training in languages beyond English firstly allows advanced artificial intelligence technologies to be accessible to a wider audience, regardless of their mother tongue. This is essential to ensure equality in digital transformation issues and to ensure a democratic advancement of technology, allowing the benefits of LLMs to reach everyone. Furthermore, training models in multiple languages enhances the intrinsic ability of these systems to handle language and its structures, as well as increasing their cultural 'baggage' and linguistic diversity, a vital detail not only in tasks such as machine translation and information search, but especially in conversational interaction, where multilingual training can ensure greater naturalness; because LLMs trained in multiple languages can pick up on language-specific nuances and contexts, including cultural particularities, popular sayings and expressions.
Finally, an interesting - and perhaps more unexplored - aspect of multilingual models is the promotion of research on underrepresented and endangered languages. The inclusion of these languages in artificial intelligence training methods contributes to better documentation of these languages and, in the future, could promote their use in the digital world, thus contributing to their preservation and revitalisation, similar to seed banks and DNA banks that store information on endangered species for potential rescue in the near future.
Spanish is one of the most widely spoken languages in the world, second in number of native speakers and fourth in number of total speakers, according to data from the Ethnologue global database. In total, more than 560 million people on five continents speak Spanish, a language that transcends geographical and cultural borders and, even today, plays a vital role in international communication and economic development. However, despite these statistics, Spanish was under-represented in LLMs, at least until the arrival of the boost provided by the Strategic Projects for Economic Recovery and Transformation (PERTE), in particular the 1.1 billion euro programme for the "new language economy". This funding programme includes the MarIA system, a language model created by the Barcelona Supercomputing Center - Centro Nacional de Supercomputación from the digital archives of the National Library. The volume and capacity of MarIA has placed Spanish at the top of the list of open access LLMs, behind only English and Mandarin. Although the first version of MarIA used a technology, called RoBERTa, based on BERT language models - systems that generate an interpretation from a sequence of text to, for example, classify documents, answer test questions, find semantic similarities in different texts - the latest version is built with GPT-2 systems that allow the system's capabilities to be extended, including the generation of new texts from a sequence. Thanks to the properties of GPT, MarIA can make automatic summaries, write complex texts from simple inputs, generate questions and answers, and even maintain complex dialogues that give the impression of naturalness.
This artificial intelligence has been trained with more than 135,000 million words, from different archives stored and catalogued by the National Library, amounting to a total of some 570 gigabytes of data. In addition, more than 9.7 trillion operations on the Mare Nostrum 4 computer at the Barcelona Supercomputing Center have been necessary to filter and catalogue all the analysed writings, eliminate all the irrelevant fragments (such as figures, unfinished sentences, anglicisms and segments in other languages) and, of course, train the neural networks of the model. According to sources at the Ministry for Digital Transformation, LLM models such as MarIA "will multiply the economic opportunities for Spanish companies and the Spanish technology industry". These systems can also be of great use for public administrations, thanks to applications such as writing, summarising legal documents, and searching for information in large text databases. Until now, all these systems were mostly developed in English, which limited applications in Spanish due to lexical and, above all, grammatical differences between the two languages.
For Elena González Blanco, a philologist and expert in artificial intelligence, the development of LLM in Spanish is "a social mission [to] give our language the status it deserves in technology". That is why she founded the company Clibrain, which works to increase the training of language models with more extensive catalogues in Spanish, including the National Library, such as the Barcelona Supercomputing Centre's MarIA system, but also the Real Academia Española, language academies in Latin America and local data, publicly available in Spain and other countries, such as newspapers, blogs, websites and digital books. In 2023, the company Clibrain presented its own LLM based on GPT-3, which they baptised with a very Iberian name: LINCE. This model is the result of a rigorous language model development and training process that uses a completely new database to deliver outstanding results in Spanish. Clibrain offers two versions of its LINCE model, ZERO, an open version released under an open source license and ZERO, an open source version released under an open source license and ZERO, an open source version released under an open source license. open source based on more than 7 billion parameters, allowing it to be used in non-commercial applications, and LINCE, an "enterprise" version with six times the size and an even more robust capability for Spanish processing, including the interpretation of dialects and area-specific features. In addition, Clibrain has also released an API - a set of rules and protocols that allow different software to communicate, essential in the development of software with integrated capabilities - that allows LINCE to be incorporated into external applications, in a similar way to that adopted by OpenAI and ChatGPT. In this way, they have developed applications such as Clichat, Clibot and Clicall, which allow interaction with LINCE in the form of chats and productivity applications.
Much more recently, in mid-April 2024, the government also announced a new collaboration with the multinational computer company IBM to encourage the development of models not only in Spanish, but also in the other co-official languages of the state - Catalan, Valencian, Galician and Basque. Expanding the models available in Spanish will help, according to IBM, to promote a more ethical use of artificial intelligence, as well as the democratisation and sustainable growth of this technology both in Spain and in Latin America and other Spanish-speaking countries. In this sense, the National Artificial Intelligence Strategy, presented in May 2024, also represents a significant advance in terms of regulating the risks and ethical implications and guarantees a development that prioritises uses in research and industry, thanks to a budget allocation of 1.5 billion euros over the next two years. Therefore, it seems that the future of artificial intelligence and, in particular, language models in Spanish is promising, with great potential to transform the way we interact both with technology and with each other in the Spanish-speaking world. The advancement of Spanish-trained LLMs, coupled with improvements in processing power and digitisation - which directly affects data availability - is expected to lead to more sophisticated and adaptive systems, ready to understand and generate Spanish text more accurately and naturally.
Technology with linguistic variants
The use of Spanish is growing at an average of 7.5% per year. The New Language Economy Project was designed with the objective of achieving an artificial intelligence (AI) capable of processing adequately in Spanish, that "thinks in Spanish", as it textually states, in order to create an industry based on technologies such as natural language processing, machine translation and conversational systems. The challenge has many complexities. Differentiating the multiple varieties of Spanish requires knowledge not only of lexical variants, but also of phonetics and even the context in which certain expressions are used, nuances that are easily lost in translation. There is the paradox that there is a large amount of data available in Spanish, but much of it cannot be used because it is often owned by private companies and, if it belongs to public and cultural institutions, it is isolated in silos and not easily accessible.
There are difficulties to overcome that are strictly material, of resource availability. The development of cutting-edge language models requires the participation of experts in artificial intelligence, computational linguistics, machine learning and other related fields, and our country suffers from a shortage of programmers and data engineers, as well as linguists and psychologists. The percentage of graduates in AI-related STEM fields barely reaches 11% of the total enrolled in universities and public centres. In fact, it has decreased by 14% between 2012 and 2022, a phenomenon with only a couple of similar cases in European countries as a whole. The result is that, in spite of the institutional messages, we are not an AI powerhouse. By the end of 2023, Spain had developed only one foundational model, compared to 109 in the US; mobilised $360 million in private investment in AI that year (US, $67.22 billion; UK, $3.78 billion; and Germany, $1.91 billion); and created 21 new AI companies (US, 897; China, 122; UK, 104; and Germany, 76). In addition, Spanish-language technology companies are generally smaller than those in the English-speaking world and are oriented towards specific functions such as translation.
The global conversational AI market is expected to reach $41.4bn by 2030, growing at a compound annual growth rate of 23.6% between 2022 and 2030. Chatbots and interactive virtual assistants could be the big beneficiaries of this expansion, thanks to the exponential leap that generative AI implies, from the early days of rule-based systems with predefined responses. Demand could therefore play a powerful role as a locomotive for innovation and development in the sector. To begin with, there is no AI capable of processing the many dialectal variants of the Spanish language, taking into account geographical, social or contextual circumstances. Developing it, including co-official languages, would imply the creation of high-value language models both in the general domain and specialised in high-impact fields such as health, education or law.
As mentioned above, one of the options is to develop the "MarIA" language model, the first artificial intelligence system expert in understanding and writing in Spanish, created within the framework of the Plan de Impulso de Tecnologías del Lenguaje Natural in collaboration with the Centro Nacional de Supercomputación and the Biblioteca Nacional de España. In parallel, an AI development in Spanish would also require the introduction of a general language comprehension assessment benchmark test, similar to the English Superglue, and a certification of the good use of Spanish in technology and AI tools. In the case of co-official languages, there are projects underway, such as Aina, Nós and the Language Technology Plan in Basque, among others, which are in addition to other initiatives in this field in Ibero-American countries, especially in the administrative context.
The Alia project, which is being developed at the MareNostrum V of the Barcelona Supercomputing Center (BSC), will work directly in Spanish and in the co-official languages of Spain, without translation. It will be an open, public and transparent infrastructure, trained with a database designed to receive contributions from institutions such as universities or professional associations, which can offer the content of their own information repositories. To work with languages with fewer resources, such as Basque and Galician, IBM Research plans to use "synthetic data", texts generated by other AIs to enrich the training database. Alongside this, the Royal Spanish Academy teamed up in 2021 for the Spanish Language and Artificial Intelligence (LEIA) project with companies such as Telefónica, Google, Amazon, Microsoft, X and Facebook. The initiative includes the creation of voice assistants, word processors, search engines, chatbots, instant messaging systems and social networks, following the criteria for good use of Spanish. LEIA was born with the aim of helping the collection of material based on the diversity of the geographical varieties of Spanish, the accessibility of AI tools and the digitisation of the RAE's own collections. In its new phase, which began in spring 2024, it has incorporated the creation of an observatory of neologisms, technical terms, terms and variations of Spanish, and tools for orthographic, grammatical and lexical verification and for answering linguistic queries.
All these steps are relevant because scientific research has shown that the root language of an AI model does affect its behaviour. Aleph Alpha, a startup from Heidelberg (Germany), created one of the world's most powerful AI language models, capable of speaking fluent English, German, French, Spanish and Italian, but it was found that its responses could differ from those produced by similar programmes developed in the US. In English, the word "the" is used to identify a specific noun, whereas in other languages, such as Spanish, the definite article is used less frequently and this complicates the creation of cues that work in both languages. As each language has different cultural standards, asking direct questions can be both impolite and polite depending on the language being used. The linguistic models trained on Chinese internet content reflect the censorship that is at the root of that information.
The adoption of the EU's Artificial Intelligence Act will help set the framework for the future. The disparity, especially in terms of available resources, calls into question the "language agnostic" status of current models. At the end of the last decade, there were more than 190 corpora developed for Spanish, co-official languages and different variants. The Corpus del Español del Siglo XXI (CORPES XXI), promoted by the Real Academia Española (RAE), would be the reference corpus, with quality annotated and detailed resources. The problem is its size, in relation to the digitised information in English, but at least it shows a level of solvency above the average for the rest of the world. A manual quality audit of 205 language-specific corpora published with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4) found that at least 15 of them had no usable text and 87 had less than 50% of acceptable quality sentences. Many were poorly labelled or used non-standard or ambiguous linguistic codes. In the case of ParaCrawl-2, it can be considered one of the most advanced, especially after the inclusion of new language pairs: those formed by Spanish and the three regional languages recognised in the country (Catalan, Basque and Galician) or the two Norwegian languages (Bokml and Nynorsk).
It is estimated that there is around 1,000 times more data in English than in Spanish, and the disproportion is accentuated in the case of the co-official languages. 5.6 % of internet content is in Spanish, compared to only 0.1% in Catalan/Valencian. The power of technology, however, can make up the difference. That is the great opportunity for innovators and those who know how to identify the need to be met. Despite being trained in English, an experiment showed that, when asked to write a headline for an article about Valencia, GPT-3 was able to write in Valencian considering the cultural particularities implicit in that speech. In 2023, ChatGPT had an average accuracy of 63.41% in 10 different reasoning categories: logical reasoning, non-textual reasoning and common sense reasoning, making it an unreliable reasoner. A year later, Open AI translated the MMLU benchmark (a set of 14,000 multiple-choice problems covering 57 topics) into 26 languages using Azure Translate: in 24 of the languages tested, it outperformed GPT-3.5 and other LLMs (Chinchilla, PaLM) in English, even in low-resource languages such as Latvian, Welsh and Swahili. English is the most well-resourced language by many orders of magnitude, but Spanish, Chinese, German and several other languages have a high enough volume of documents to build equally sophisticated language models.
At the global level, the problem is not strictly technological, but one of visibility. Communities with limited internet access are under-represented online, which distorts the textual data available to train generative AI tools and fuels a phenomenon known as prestige transfer.[26] which states that American English is the "standard" and dominant mode of discourse, and any stylistic deviations in pronunciation or grammar are perceived as inferior or incorrect. The latest version, ChatGPT-4, scored 85% on a common question and answer test in English, but in Telugu, an Indian language spoken by nearly 100 million people, it stood at 62%.
In general, ChatGPT's performance is usually better for English prompts, especially for higher-level tasks that require more complex reasoning skills, even if the input texts are written or expected to be answered in other languages. Their behaviour worsens when answering objective questions or summarising complex texts in languages other than English, in which circumstances they are more likely to invent information. The models perform better on tasks that involve switching from language X to English than on tasks that involve switching from English to English. In an April 2023 exercise, NewsGuard provided ChatGPT-3.5 with seven messages in English, Simplified Chinese and Traditional Chinese, and asked it to produce news stories promoting disinformation narratives related to China. For the English exercise, ChatGPT refused to present false claims in six out of seven messages. However, it produced the false articles in simplified Chinese and traditional Chinese all seven times. Precisely in the field of journalistic reporting, and to address concerns about the use of proprietary resources, OpenAI has entered into partnerships that include Spain's Prisa Media, France's Le Monde and Germany's Axel Springer, in addition to its collaborations with the American Journalism Project, to support innovative local news initiatives, and The Associated Press.
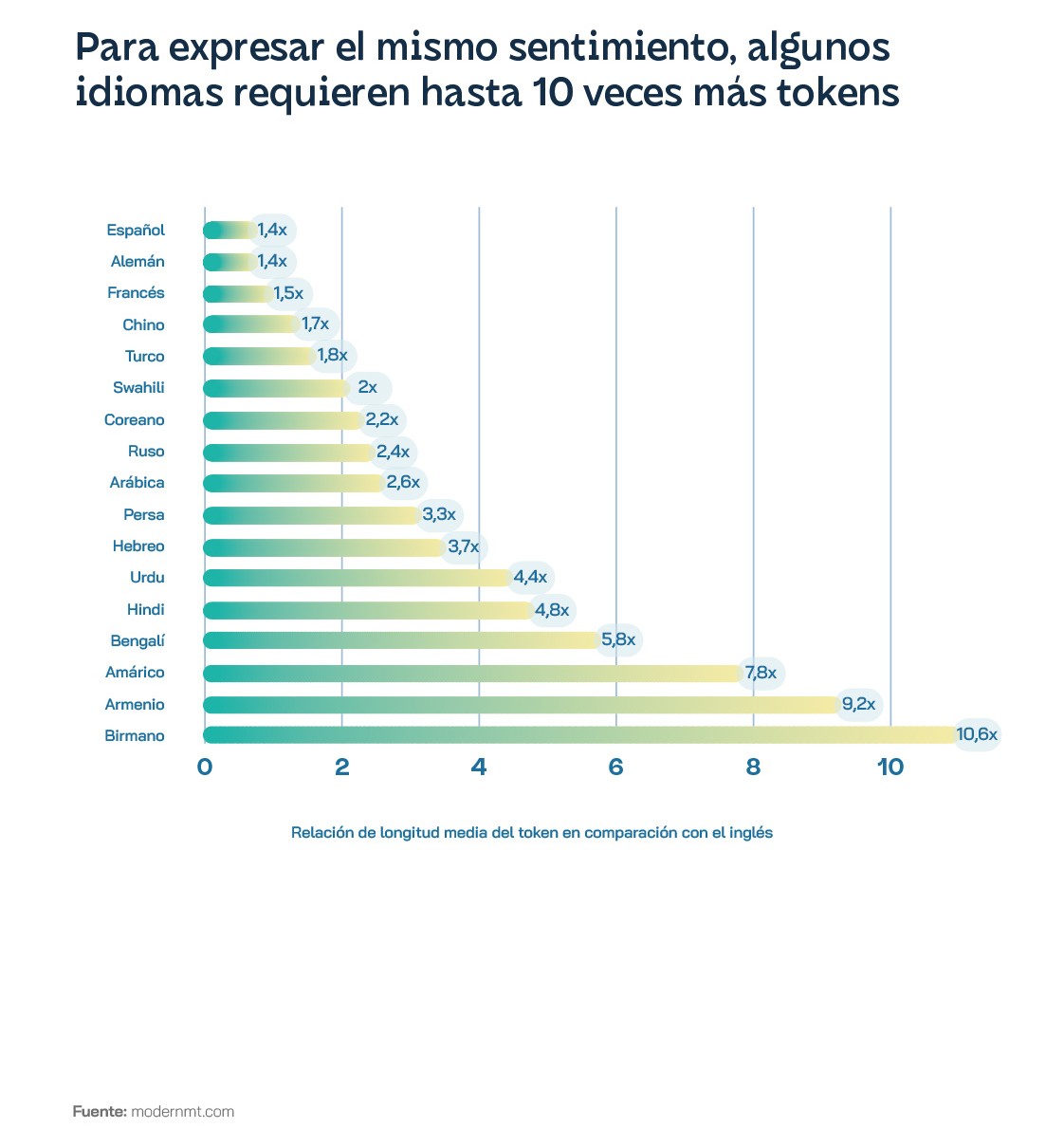
In addition to the problem of data scarcity, there is the increased cost: using GPT-4 in languages other than English can cost up to 15 times more, due to tokenisation, despite being less effective. Languages such as Hindi and Bengali, spoken by more than 800 million people, have an average token length that is about five times that of English, Armenian nine times that of English, and Burmese more than 10 times that of Burmese. All this translates into tokens, whose allocation pattern disproportionately favours Latin-script languages and overly fragments the lesser-represented scripts. This is no small matter considering that the United States alone accounted for 10% of the traffic sent to ChatGPT between January and March 2023. Language models have evolved from research prototypes to commercialised products offered as web APIs, which charge their users according to usage, or to be more precise, by the number of tokens processed by the underlying language models.
Some researchers argue that, under the current circumstances, it makes more sense to build smaller task-specific models for PLN (natural language processing) problems that can be hosted locally and run at lower costs. RigoBERTa is a Spanish language model from the Institute of Knowledge Engineering (IIC) of the Autonomous University of Madrid designed to adapt to different language domains, such as legal or health, to improve PLN applications. It is intended to be applied at a production or business level and not at a user level like most generative models. Interestingly, the performance of Chat GPT for low and extremely low resource languages on some tasks is sometimes better or comparable to that of high or medium resource languages. This might indicate that the size of the data might not be the only factor determining its performance: the target task and the similarities and relationships of a language with respect to other dominant languages in the LLM training data also play a role.
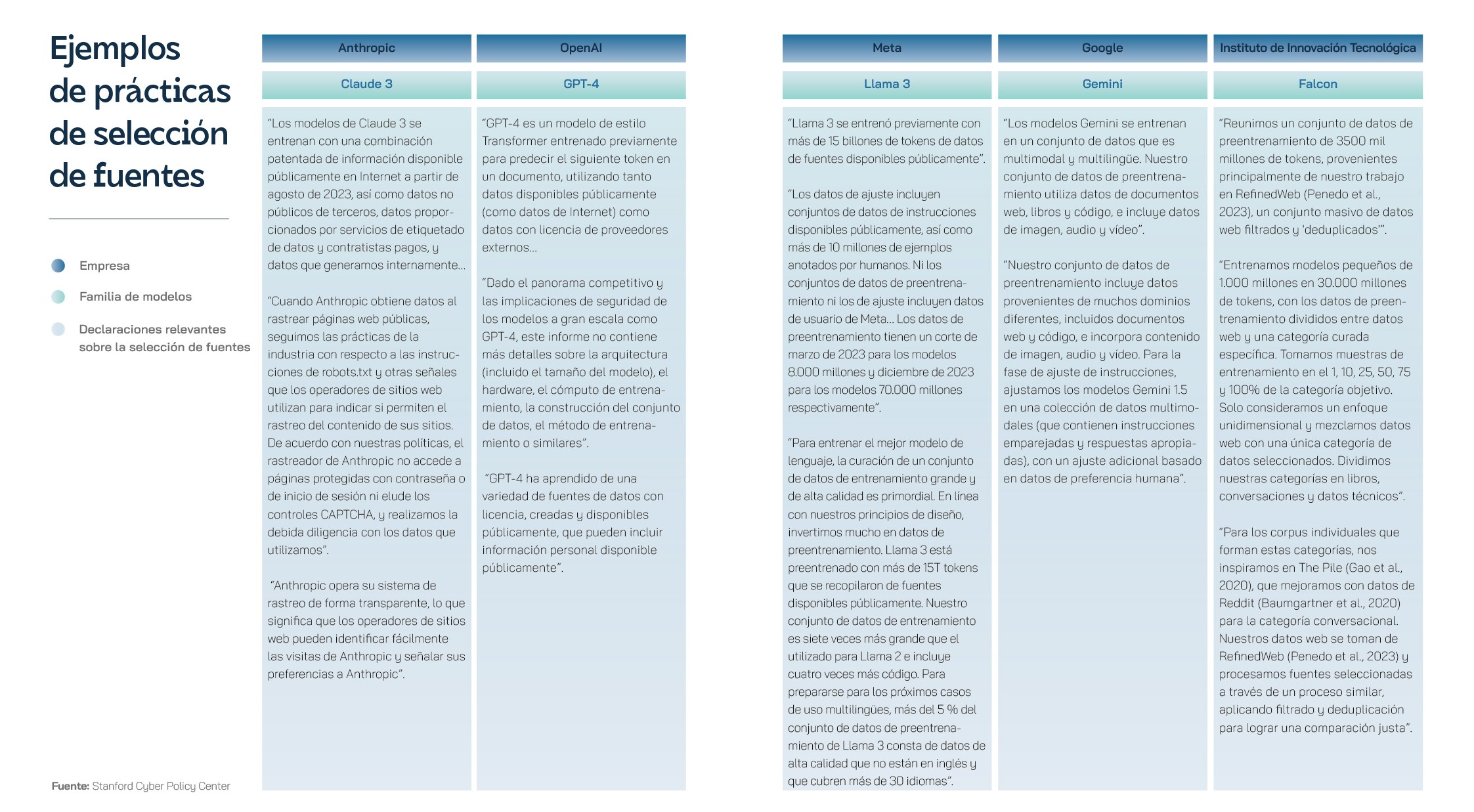
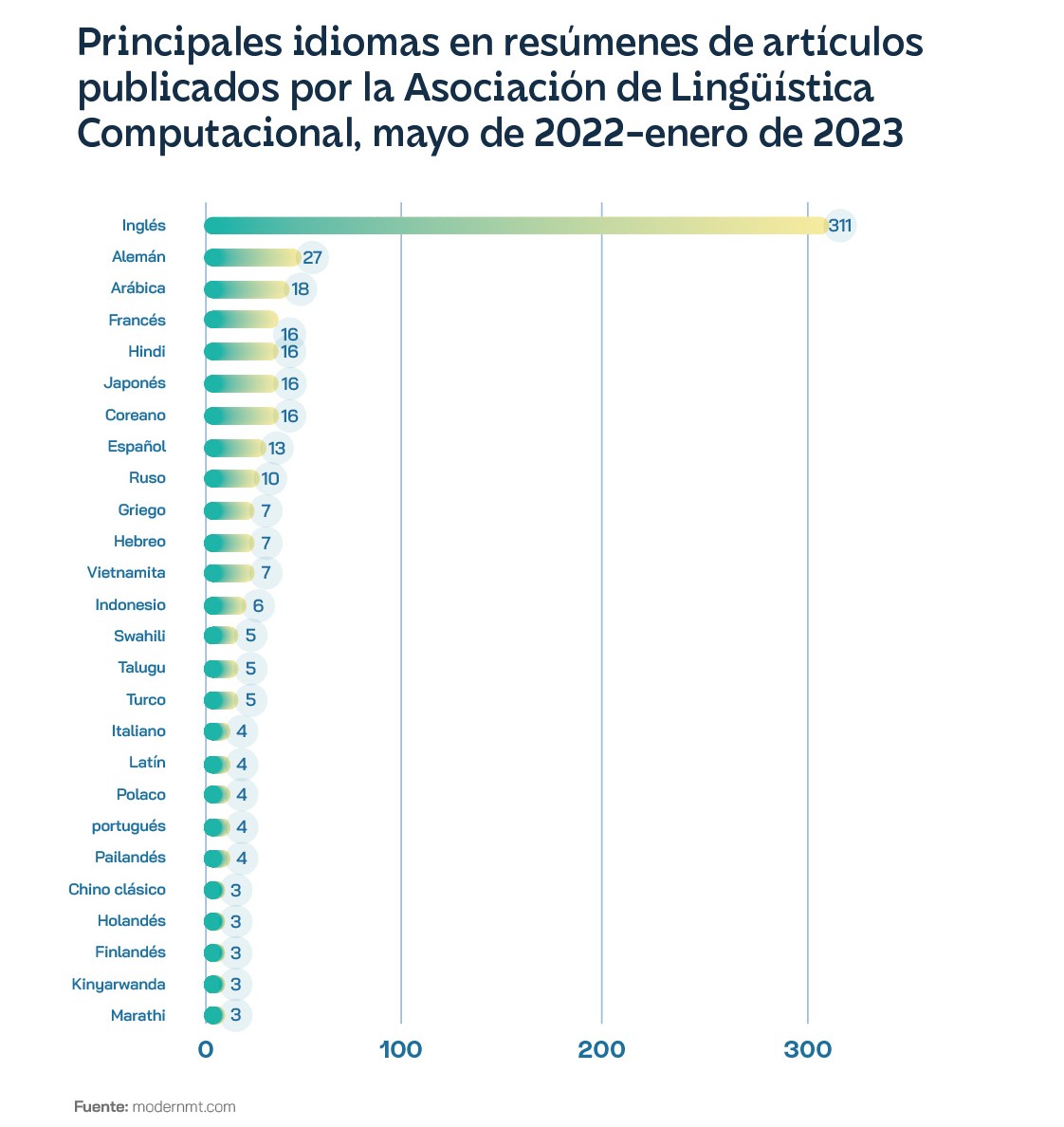
English is the main language of the Internet with 63.7% of websites, despite the fact that it is spoken by only 16% of the world's population. Among scientific articles on PLN, English is mentioned ten times more than the next most common, German. As research grows, labelled data increases, which can be used for model quality, in what ends up being a virtuous circle for PLN in English, despite the fact that there are six other languages that could be considered high-resource languages: the official UN languages, minus Russian and plus Japanese. Even technology companies are aware of this situation and have been working to expand the number of language models in which their solutions work. They are doing so by creating more datasets, with projects such as Facebook's No Language Left Behind and Google's 1000 Languages Initiative. The latter company's BERT model architecture, one of the most popular and cheapest to train, has been used for French (CamemBERT), Italian (AlBERTo), Arabic (AraBERT), Dutch (BERTje), Basque (BERTeus), Maltese (BERTu) and Swahili (SwahBERT), among others. Concerned about the implications for the effectiveness of defence systems, the US Defense Advanced Research Projects Agency (DARPA) funded the Low Resource Languages for Emerging Incidents (LORELEI) programme in 2014. Instead of using monolingual models to perform NLP tasks, researchers often use multilingual language models, such as Google's aforementioned mBERT and Meta's XLM-R, which are trained from texts from many different languages at once on the same fill-in-the-blank task. It is understood that they can infer connections between languages and thus act as a kind of bridge between high and low resourcers. However, the reality is that multilingual models work by transferring between linguistic contexts, and this often means that higher-resource languages overwrite lower-resource languages. Spanish uses more adjectives and analogies than English to describe extreme situations, so an English sentiment detection algorithm could mischaracterise a text written in Spanish. Languages do not necessarily inform each other, they are overlapping but distinct areas of the dataset, and the model has no way of comparing whether certain phrases or predictions differ between those areas. In short, the more languages a multilingual model is trained on, the less it can capture the unique features of any specific language. This is known as the curse of multilingualism.
Language technology in the field
The challenge of artificial intelligence in Spanish has been addressed in recent years as a public challenge, which has been joined by technology corporations such as Telefónica and IBM as providers of support infrastructure and R&D services, as well as entities such as the Barcelona Supercomputing Center. For the Director of the Instituto Cervantes, the most important linguistic and cultural challenge of the 21st century for Spain's main cultural institutions is "to teach Spanish to machines and for them to help us teach it". From his institution, he continues in some reflections published on the institute's website, "we will promote the design of robust, reliable and transparent AI systems that prevent inappropriate or misuse of technology, especially through confusing, ambiguous or biased expressions in language". According to Luis García Montero, "algorithms must broaden the appeal of our language in all its diversity, of the pan-Hispanic culture that accompanies it and of our common industries". Ultimately, "machines will use formulas, words, images, designs and clear expressions using all the nuances of our languages, the importance of context and the way we humans communicate with each other". The main measure put in place to exercise this governance has been the creation of the Global Observatory of Spanish, which held the first meeting of its executive committee in March 2024. The Cervantes Institute hopes that it will serve, among other things, to determine the way in which artificial intelligence and machine language should be supported so that they do not create supremacist biases, among other problems and risks they entail.
In parallel, the LEIA (Spanish Language and Artificial Intelligence) project also entered its second phase in 2024, under the leadership of the Royal Spanish Academy and with the participation as technological partners of Fujitsu, which is based on Amazon Web Services (AWS) solutions, and the North American VASS. There is no Spanish technology, for the moment. At this stage, an observatory of neologisms, terms and variations of Spanish will be created, a tool capable of automatically detecting, in the digital universe and from a large number of sources, words and expressions that are not yet registered in the Diccionario de la lengua española (DLE), whether they are neologisms, derivatives, technical terms, regionalisms or foreign words. On the other hand, an open linguistic verifier will be created, hosted on the LEIA website and accessible from the RAE website. It will allow users to enter a text to check whether it is correct from an orthographic, grammatical and lexical point of view. In connection with this initiative, the project also envisages the creation of a tool to answer Spanish speakers' linguistic queries. The second phase of LEIA also includes the collection of material representative of the different geographical varieties of Spanish, especially lexical and oral. To this end, an interactive section will make it possible to provide information in relation to images, texts or other elements shown to them. Citizen participation, in this sense, will be key because users will be asked to describe an image with their own voice, thus creating an oral corpus to train the systems or applications in the different accents. LEIA will make openly available to the public the materials used to generate the project, from source code to data or training corpus, with the intention of boosting the Spanish language technology industry.